Announcing PyCaret 3.0 — An open-source, low-code machine learning library in Python
Exploring the Latest Enhancements and Features of PyCaret 3.0
In this article:
- Introduction
- Stable Time Series Forecasting Module
- New Object Oriented API
- More options for Experiment Logging
- Refactored Preprocessing Module
- Compatibility with the latest sklearn version
- Distributed Parallel Model Training
- Accelerate Model Training on CPU
- RIP: NLP and Arules module
- More Information
- Contributors
Introduction
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows. It is an end-to-end machine learning and model management tool that exponentially speeds up the experiment cycle and makes you more productive.
Compared with the other open-source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with a few lines only. This makes experiments exponentially fast and efficient. PyCaret is essentially a Python wrapper around several machine learning libraries and frameworks in Python.
The design and simplicity of PyCaret are inspired by the emerging role of citizen data scientists, a term first used by Gartner. Citizen Data Scientists are power users who can perform both simple and moderately sophisticated analytical tasks that would previously have required more technical expertise.

To learn more about PyCaret, check out our GitHub or Official Docs.
Check out our full Release Notes for PyCaret 3.0
📈 Stable Time Series Forecasting Module
PyCaret’s Time Series module is now stable and available under 3.0. Currently, it supports forecasting tasks, but it is planned to have time-series anomaly detection and clustering algorithms available in the future.
# load dataset
from pycaret.datasets import get_data
data = get_data('airline')
# init setup
from pycaret.time_series import *
s = setup(data, fh = 12, session_id = 123)
# compare models
best = compare_models()
# forecast plot
plot_model(best, plot = 'forecast')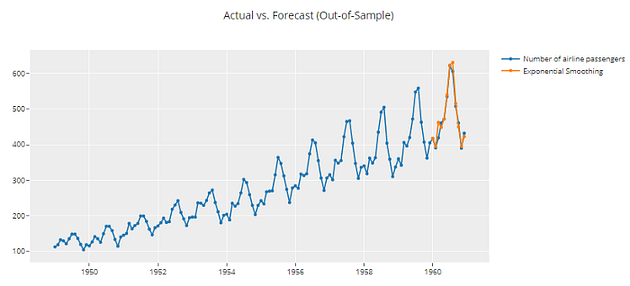
# forecast plot 36 days out in future
plot_model(best, plot = 'forecast', data_kwargs = {'fh' : 36})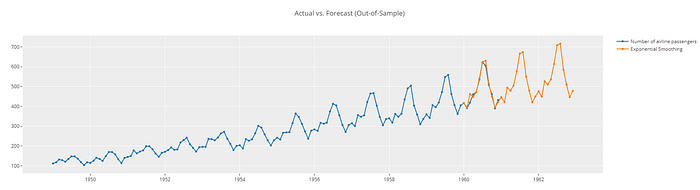
💻 Object Oriented API
Although PyCaret is a fantastic tool, it does not adhere to the typical object-oriented programming practices used by Python developers. To address this issue, we had to rethink some of the initial design decisions we made for the 1.0 version. It is important to note that this is a significant change that will require considerable effort to implement. Now, let’s explore how this will affect you.
# Functional API (Existing)
# load dataset
from pycaret.datasets import get_data
data = get_data('juice')
# init setup
from pycaret.classification import *
s = setup(data, target = 'Purchase', session_id = 123)
# compare models
best = compare_models()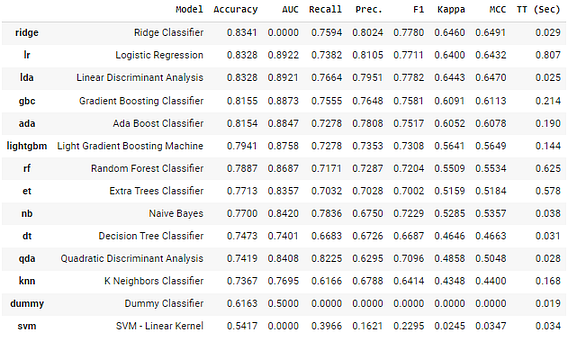
It's great to do experiments in the same notebook, but if you want to run a different experiment with different setup function parameters, this can be a problem. Although it is possible, the previous experiment’s settings will be replaced.
However, with our new object-oriented API, you can effortlessly conduct multiple experiments in the same notebook and compare them without any difficulty. This is because the parameters are linked to an object and can be associated with various modeling and preprocessing options.
# load dataset
from pycaret.datasets import get_data
data = get_data('juice')
# init setup 1
from pycaret.classification import ClassificationExperiment
exp1 = ClassificationExperiment()
exp1.setup(data, target = 'Purchase', session_id = 123)
# compare models init 1
best = exp1.compare_models()
# init setup 2
exp2 = ClassificationExperiment()
exp2.setup(data, target = 'Purchase', normalize = True, session_id = 123)
# compare models init 2
best2 = exp2.compare_models()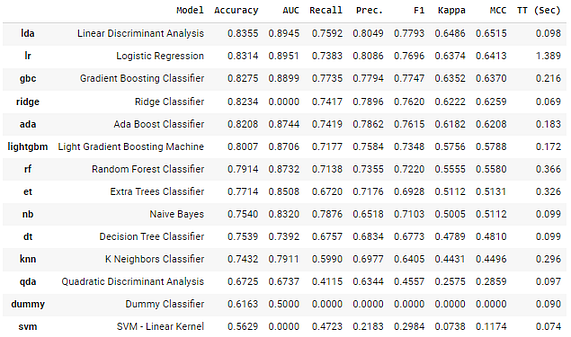
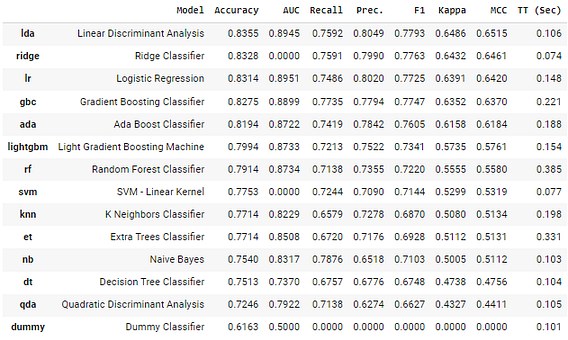
After conducting experiments, you can utilize the get_leaderboard function to create leaderboards for each experiment, making it easier to compare them.
import pandas as pd
# generate leaderboard
leaderboard_exp1 = exp1.get_leaderboard()
leaderboard_exp2 = exp2.get_leaderboard()
lb = pd.concat([leaderboard_exp1, leaderboard_exp2])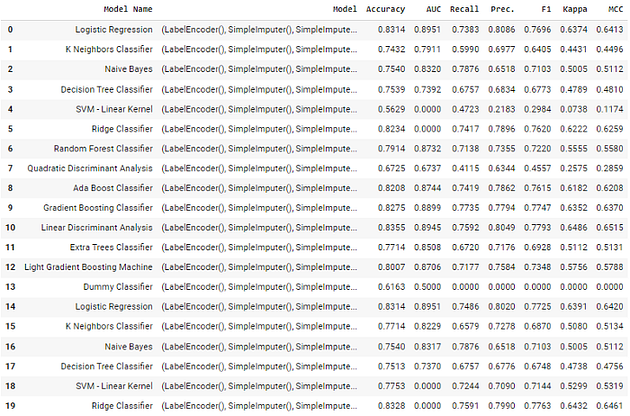
# print pipeline steps
print(exp1.pipeline.steps)
print(exp2.pipeline.steps)
📊 More options for Experiment Logging
PyCaret 2 can automatically log experiments using MLflow . While it is still the default, there are more options for experiment logging in PyCaret 3. The newly added options in the latest version are wandb, cometml, dagshub .
To change the logger from default MLflow to other available options, simply pass one of the following in thelog_experiment parameter. ‘mlflow’, ‘wandb’, ‘cometml’, ‘dagshub’.
🧹 Refactored Preprocessing Module
The preprocessing module underwent a complete redesign to improve its efficiency and performance, as well as to ensure compatibility with the latest version of Scikit-Learn.
PyCaret 3 includes several new preprocessing functionalities, such as innovative categorical encoding techniques, support for text features in machine learning modeling, novel outlier detection methods, and advanced feature selection techniques.
Some of the new features are:
- New categorical encoding methods
- Handling text features for machine learning modeling
- New methods to detect outliers
- New methods for feature selection
- Guarantee to avoid target leakage as the entire pipeline is now fitted at a fold level.
✅ Compatibility with the latest sklearn version
PyCaret 2 relies heavily on scikit-learn 0.23.2, which makes it impossible to use the latest scikit-learn version (1.X) simultaneously with PyCaret in the same environment.
PyCaret is now compatible with the latest version of scikit-learn, and we would like to keep it that way.
🔗 Distributed Parallel Model Training
To scale on large datasets, you can run compare_models function on a cluster in distributed mode. To do that, you can use the parallel parameter in the compare_models function.
This was made possible because of Fugue, an open-source unified interface for distributed computing that lets users execute Python, Pandas, and SQL code on Spark, Dask, and Ray with minimal rewrites
# load dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# init setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable', n_jobs = 1)
# create pyspark session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# import parallel back-end
from pycaret.parallel import FugueBackend
# compare models
best = compare_models(parallel = FugueBackend(spark))
🚀 Accelerate Model Training on CPU
You can apply Intel optimizations for machine learning algorithms and speed up your workflow. To train models with Intel optimizations use sklearnex engine, installation of Intel sklearnex library is required:
# install sklearnex
pip install scikit-learn-intelexTo use the intel optimizations, simply pass engine = 'sklearnex' in the create_model function.
# Functional API (Existing)
# load dataset
from pycaret.datasets import get_data
data = get_data('bank')
# init setup
from pycaret.classification import *
s = setup(data, target = 'deposit', session_id = 123)Model training without intel accelerations:
%%time
lr = create_model('lr')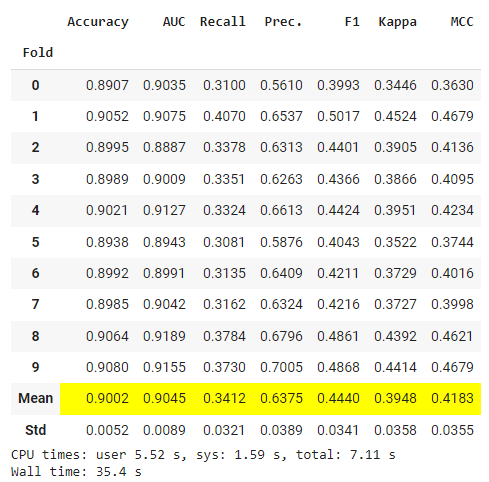
Model training with intel accelerations:
%%time
lr2 = create_model('lr', engine = 'sklearnex')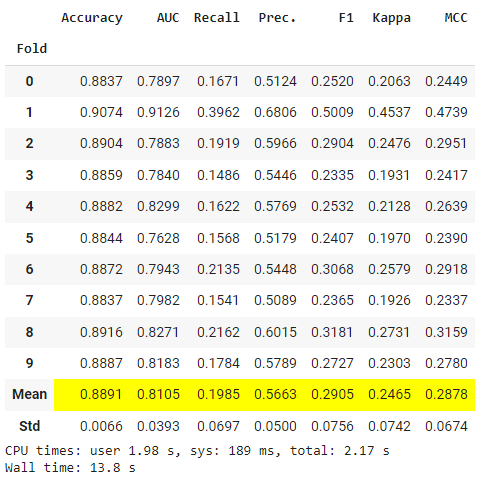
There are some differences in model performance (immaterial in most cases) but the improvement in timing is ~60% on a 30K rows dataset. The benefit is much higher when dealing with larger datasets.
⚰️ ️RIP: NLP and Arules module
NLP is changing fast, and there are many dedicated libraries and companies working exclusively to solve end-to-end NLP tasks. Due to lack of resources, existing expertise in the team, and new contributors willing to maintain and support NLP and Arules, we have decided to drop them from PyCaret. PyCaret 3.0 doesn’t have nlp and arules module. It has also been removed from the documentation. You can still use them with the older version of PyCaret.
ℹ️ More Information
📚 Docs Getting started with PyCaret
📝 API Reference Detailed API docs
⭐ Tutorials New to PyCaret? Check out our official notebooks
📋 Notebooks created and maintained by the community
📙 Blog Tutorials and articles by contributors
📺 Videos Video tutorials and events
🎥 YouTube Subscribe our YouTube channel
🤗 Slack Join our slack community
💻 LinkedIn Follow our LinkedIn page
📢 Discussions Engage with the community and contributors
Contributors
Thanks to all the contributors who have participated in PyCaret 3.
@ngupta23
@Yard1
@tvdboom
@jinensetpal
@goodwanghan
@Alexsandruss
@daikikatsuragawa
@caron14
@sherpan
@haizadtarik
@ethanglaser
@kumar21120
@satya-pattnaik
@ltsaprounis
@sayantan1410
@AJarman
@drmario-gh
@NeptuneN
@Abonia1
@LucasSerra
@desaizeeshan22
@rhoboro
@jonasvdd
@PivovarA
@ykskks
@chrimaho
@AnthonyA1223
@ArtificialZeng
@cspartalis
@vladocodes
@huangzhhui
@keisuke-umezawa
@ryankarlos
@celestinoxp
@qubiit
@beckernick
@napetrov
@erwanlc
@Danpilz
@ryanxjhan
@wkuopt
@TremaMiguel
@IncubatorShokuhou
@moezali1
Liked the blog? Connect with Moez Ali
Moez Ali is an innovator and technologist. A data scientist turned product manager dedicated to creating modern and cutting-edge data products and growing vibrant open-source communities around them.
Creator of PyCaret, 100+ publications with 500+ citations, keynote speaker and globally recognized for open-source contributions in Python.
Let’s be friends! connect with me:
👉 LinkedIn
👉 Twitter
👉 Medium
👉 YouTube
🔥 Check out my brand new personal website: https://www.moez.ai.
To learn more about my open-source work: PyCaret, you can check out this GitHub repo or you can follow PyCaret’s Official LinkedIn page.
Listen to my talk on Time Series Forecasting with PyCaret in DATA+AI SUMMIT 2022 by Databricks.
